Notes from Zero Knowledge Summit 2024
The 11th edition of the Zero Knowledge Summit took place in Athens on April 10th, 2024, at the Eugenides Planetarium. The event hosted 500 attendees, including researchers, cryptographers, practitioners, founders, and developers working on zero knowledge topics.

The topics discussed at the zkSummit included zkVM, proving networks, hardware acceleration, data provenance, privacy-preserving identity (selective disclosure), and client-side proving.
This article includes notes from most of the talks, focusing on the problem, solution, and future directions.
As an engineer myself, I have organized the talks from applications to technical to business discussions. At the end, I provide my subjective conclusion.
Anonymous Credentials Based on Programmable Zero-Knowledge, Johannes Sedlmeir Talk
India successfully introduced Aadhaar. Soon, every country in the EU will use European digital identity (eID).
Problem: The certificate includes more information than what the holder is usually aware of and what the verifier needs to know.

Solution: Selective disclosure. We don’t have to show the whole ID/certificate, but only prove what needs to be proven.

For instance, we can prove maturity via range proofs, membership inclusion instead of citizenship, and a “not before” range proof instead of an expiration date.
There are already solutions, but they rely on trusted hardware components. We don’t want that. We can do better with zkSNARKs.
Anonymous credentials based on zero-knowledge proofs, sometimes called “attribute-based credentials,” are used by huge consortia. They use specialized and efficient sigma protocols. However, they are complex, tedious to work with, and error-prone.
General-purpose ZKPs are like duct tape, but after recent advances, they may work well (see zk-creds).
The biggest problem right now is client-side performance on mobile phones. Zk-friendly crypto works fine, but non-zk-friendly can take 30s-1min. We need to get closer to 1 second. We need to lobby for standardization and security assessment by a government body (e.g., ETSI, BSI). We need a revocation mechanism that scales.
Future improvements:
- Blind the credentials, outsource proof generation to a server, and unblind the result.
- Binary fields for more efficient SHA256 hashing.
Implementing an anonymous credential system in the real world is highly complex because we need to satisfy a lot of business and regulatory requirements.
ZkPassport and Electronic ID Verification, Théo Madzou Talk Slides, Michael Elliot & Derya Karli Talk Slides
Most of our passports are equipped with RFID chips that contain all the information in the passport: name, surname, nationality, photo, birth date, and a digital signature over all the data. The signature is generated by the state that issued the passport. Everything is standardized by ICAO.

Problem: How can I prove my maturity without disclosing my age? Or prove I’m an EU citizen without disclosing my nationality? Or prove my surname without revealing anything else on my passport?
Solution: Selective disclosure! Generate a ZKP that attests to all the checks.
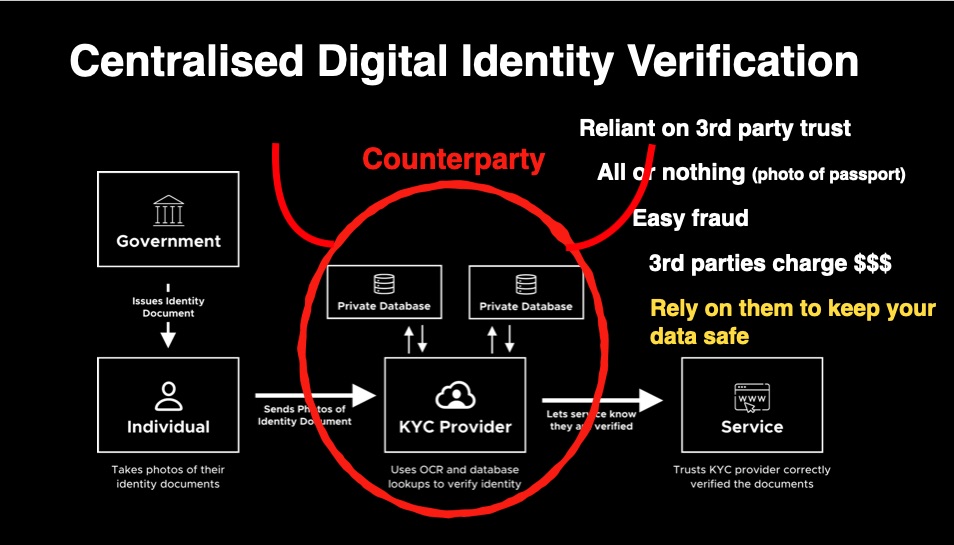
They also build a cross-platform mobile apps that can scan the chip of a passport and generate a zk proof from it.
In theory, it’s illegal to scan these chips without government authorization, but in practice, no one verifies that.
Mopro: Client-Side Proving on Mobile Made Easy, Oskar Thoren Talk
Mopro is a toolkit for ZK app development on mobile.
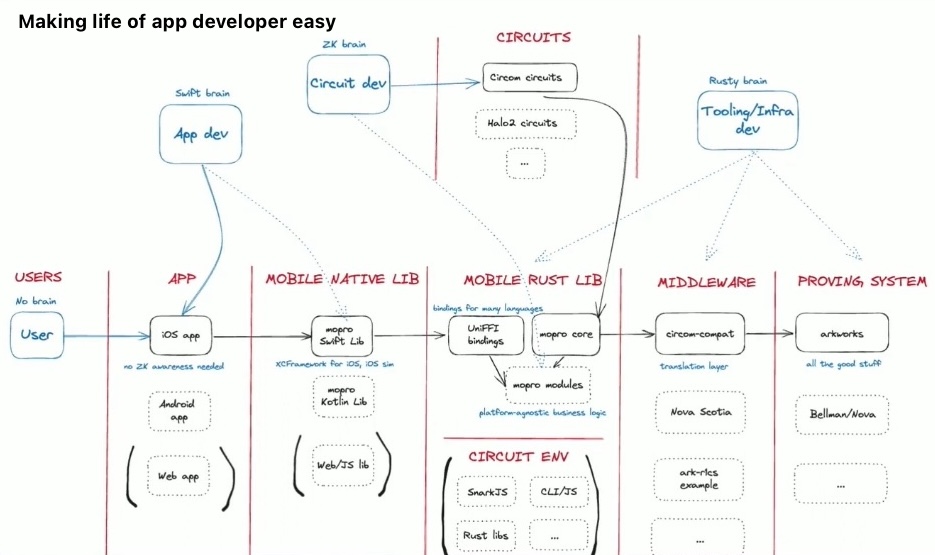
Client-side proving is important for identity systems like Zupass, zkPassport, Anon Aadhaar, and everywhere where privacy and selective disclosure are important.
The bottleneck for mobile is memory, not CPU.
CPU power slows things down, while memory crashes.
Anon-Aadhaar has 1.6M constraints.
1.6M constraints = 2GB memory
Proteus AI Data Provenance, Daniel Bessonov & Rohan Sanjay Slides Talk
Problem: We don’t know where images come from, whether they are real or generated by tools like Stable Diffusion, Sora, or Midjourney. This leads to the spread of misinformation.
Policymakers want to regulate AI. Can we do better?
Problem: Embedding metadata into and alongside an image is challenging.
Image watermarking doesn’t work because compression, cropping, and screenshots corrupt the watermarks. Encoding the metadata alongside the image doesn’t work because it’s easy to lose or remove that metadata.
Solution: Track content regardless of modification and prove that modified content came from the original.
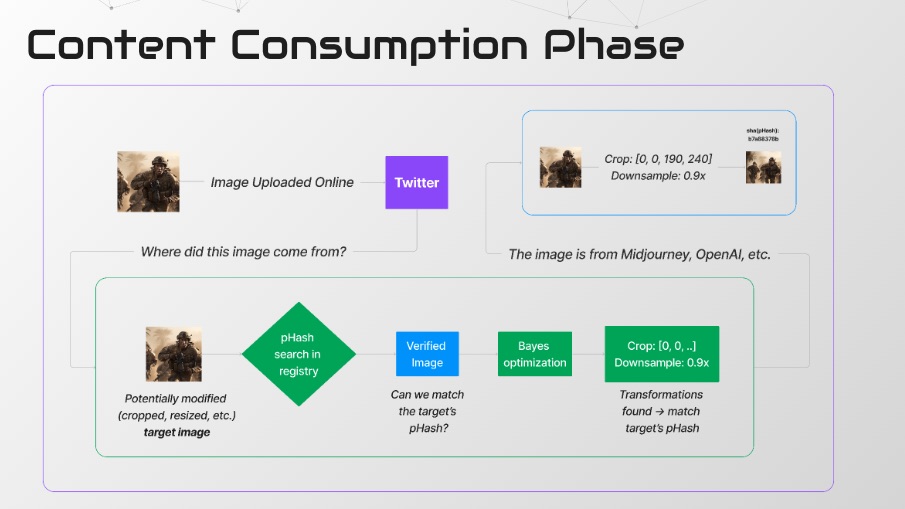
When an image is created, its perceptual hash is computed and stored in a private registry. The perceptual hashes are cryptographically hashed and committed to public data storage, along with metadata and signatures.
Flow:
- User scrolls Twitter and stumbles upon a suspicious image.
- User computes the perceptual hash of the image and checks the internal registry for a similar hash.
- If yes, the registry performs a Bayesian optimization process to figure out which set of transformations (cropping, scaling, compression, brightness, etc.) applied to the original can lead to the target image.
- To prove that the image is modified without revealing the original, they generate a ZKP that there is an original image that applied to the set of transformations leading to perceptual hashes close to the original.
ZK Email: Novel ZK Applications Unlocked by Portable Provenance, Aayush Gupta & Sora Suegami Slides Talk
Problem: It’s hard to bring off-chain data on-chain in a verifiable manner without using attesters that rely on MPCs, oracles, or enclaves.
Solution: Don’t use attestation, use provenance data!
Provenance data works as follows:
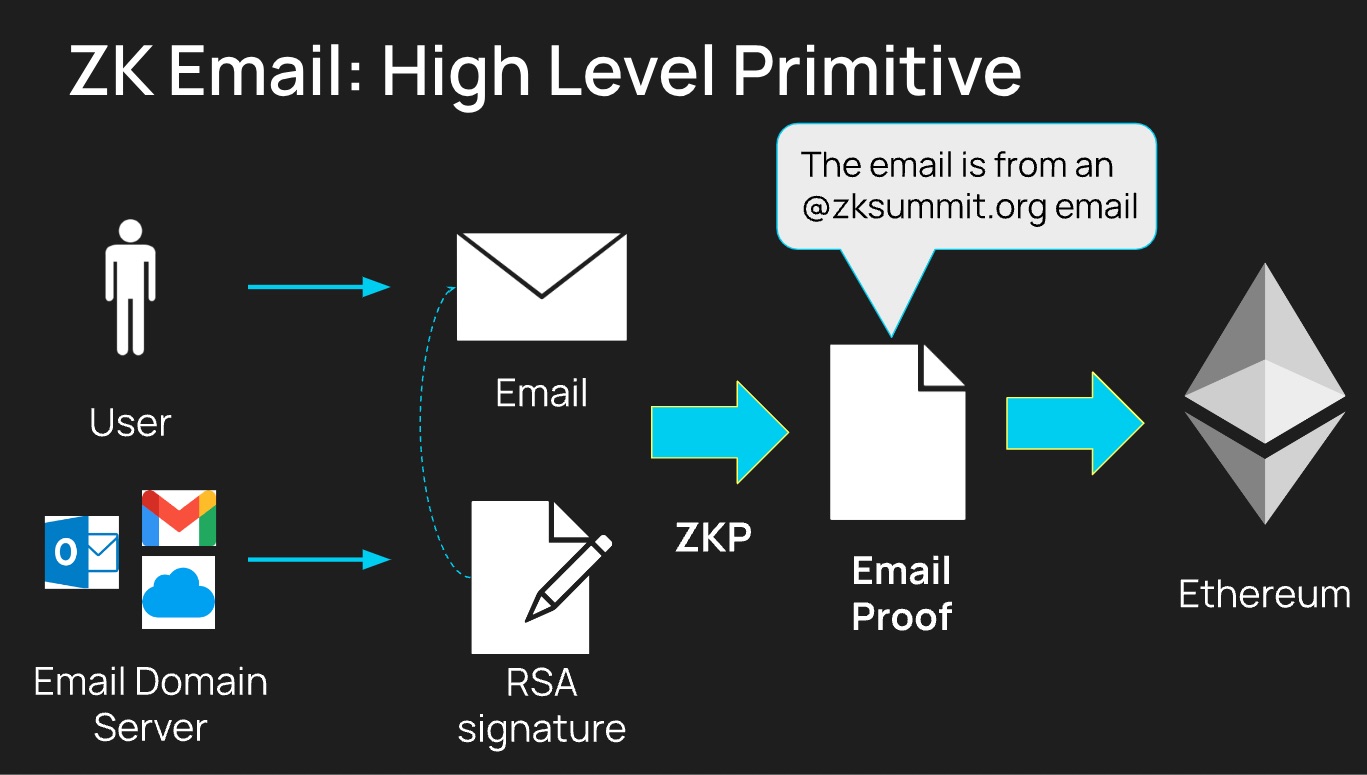
- When any user on any email server sends an email, an RSA signature is automatically attached since 2017.
- The signature, sender, title, and content are verified inside a zk circuit, attesting to the statement “I received an email from @zksummit.org.”
- The proof can be posted on-chain, giving it provenance.
- Additional checks can be “programmed” by zk-regex that will be executed on the email content, e.g., “I successfully sent $100 via PayPal transaction to account @xyz.”
To verify the email signature, we verify it against the RSA public key, which is found on DNS at selector._domainkey.example.com -> RSA pubkey.
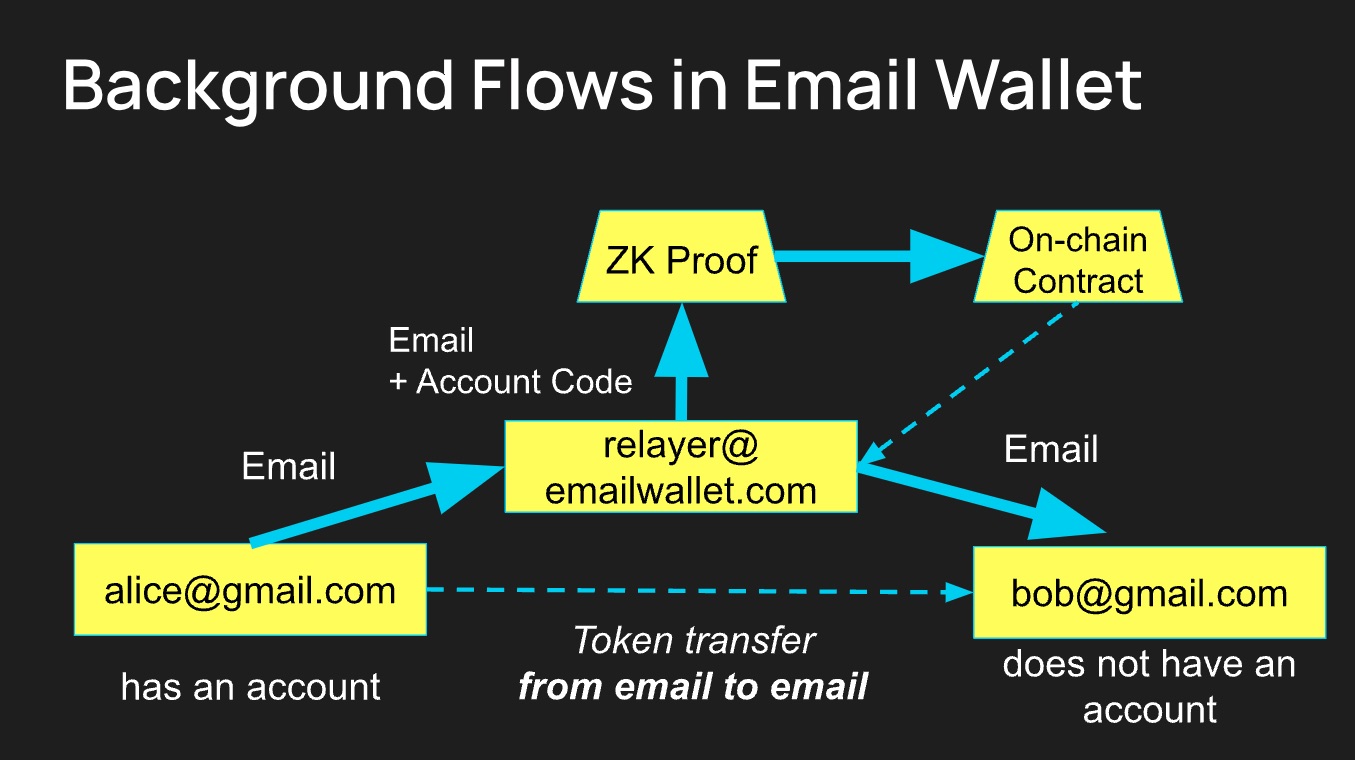
The architecture introduces a semi-honest party called Relayer, which plays the role of web server, SMTP relayer, ERC-4337 bundler, and prover.
Account creation:
- To create a ZK Email wallet, the user has to initialize the account creation by entering their email address ([email protected]) into a Relayer web app.
- The Relayer ([email protected]) sends an email along with an Account Code.
- The Account Code is used for privacy protection and Relayer decentralization.
- The hash(email address, account code) = CREATE2’s salt of the user’s Ethereum address.
- Hence, the adversary cannot guess the email by brute-force hashing.
As long as the user has access to the Account Code (stored in their inbox), they can use different relayers, ensuring decentralization.
Email wallet flow:
- The user initializes a transfer from the Relayer website.
- The Relayer sends an email to the user asking for confirmation.
- The user confirms by sending an email back to the Relayer.
- The confirmation email is turned into a zkSNARK and published on-chain via the Relayer ERC4337 bundler, utilizing smart wallet functionality.
ZK Email SDK allows for building on top of the infrastructure, specifying own regexes, and issuing transactions via emails. Email-Based Account Recovery allows specifying guardians by email addresses, so they don’t need to be crypto users.
ZK Email uses Circom and Halo2.
Aptos Keyless: Blockchain Accounts without Secret Keys, Alin Tomescu (Aptos Labs) Talk Slides
Problem:
- People lose their private keys.
- A separate wallet app is problematic.
- Many per-chain wallets are overwhelming.
Goal:
- Walletless (no separate app).
- No mnemonic.
- Hard to lose.
- Avoid transaction prompts.
- Cross-device.
- KYC via OIDC.
- Pay-to-email.
Keyless accounts (addresses) are app-specific and are derived from (Email address, Application ID). Keyless TXN signature = OIDC signature from Google/Github/Facebook, etc.
OIDC works as follows:
- App sends a request to Google with client_id and nonce.
- Google returns Sign(SK, {uid: email, app: client_id, nonce}).
- Everyone can verify the signature knowing Google’s PK.
The idea of a keyless account is to include the transaction in the nonce and verify the signature on the blockchain, using it to execute the transaction.
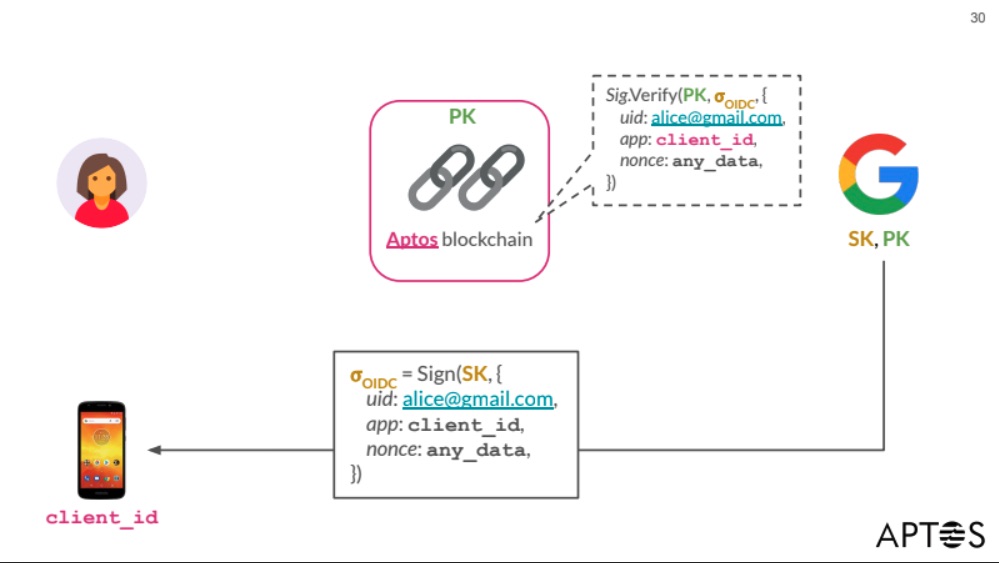
To make it privacy-preserving, instead of providing the whole data in plaintext, we calculate the address as a commitment H(email, client_id, pepper), and prove its validity in ZK.
ZkSnap - End-to-End Private Voting at No Cost to Users, Rahul Ghangas (Aerius Labs) Talk
Problems:
- Traditional DAO voting systems depend heavily on trusted third parties to generate a snapshot of eligible voters.
- Voting has to be private; otherwise, people vote on what’s popular (bandwagon effect).
- Ballots must be confidential; otherwise, voters may be vulnerable to surveillance and coercion.
- Almost none of the voting systems achieve bribery (coercion) resistance.
Solutions:
- Instead of using a snapshot of eligible voters, each voter generates storage proofs that attest to a predicate like “I’ve been part of the DAO for 1k blocks.”
- Prevent double voting using nullifiers.
- Keep voting encrypted using Paillier homomorphic encryption to aggregate individual encrypted ballots and decrypt only the total results.
- Permissionless decryption using time-lock encryption via DRAND.
- Free, because voters don’t publish on-chain; instead, they submit to a centralized aggregator.
The biggest problem is that zkSNAP relies on a (semi)-honest third party, the Aggregator.
Problems:
- Voters don’t publish votes on-chain but send them to the aggregator (so it’s free).
- The aggregator can censor transactions at will.
- The aggregator can accept votes after the voting period has finished.
- Whoever generates the private key (before it gets encrypted with a time-lock puzzle) can:
- decrypt individual ballots and associate them with the sender.
- decrypt votes in-flight before the deadline.
- It’s not coercion-resistant because voters can prove their vote was included in the voting.
Suggestion:
- Use key holders and DKG to collectively generate the private key.
Protecting against Bad Actors in Private Systems, Damian Straszak (Aleph Zero) Talk
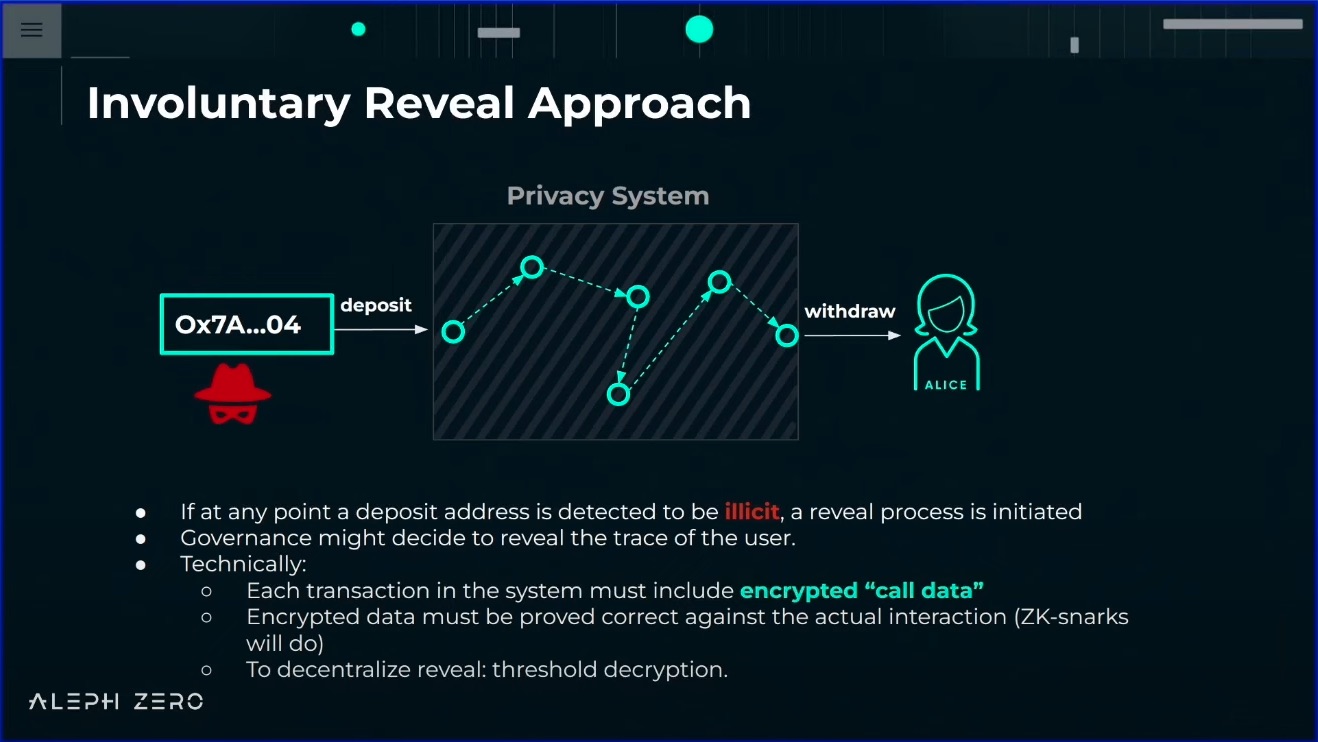
Blockchain Privacy Systems work as follows:
- There is a user with a public address.
- The user enters the private system by depositing funds.
- They make transactions.
- The trace inside this private system is hidden.
- The user can withdraw the funds to a new address.
Problem:
- Privacy systems can be used for illicit activities.
- A privacy system should never freeze, slash, or confiscate funds.
- Unless we solve this problem, we can’t make blockchain private by default. There’s no silver bullet yet.
The highest “penalty” in a private system has to be deanonymization. No one will voluntarily reveal their track of illicit activities.
Possible solutions:
- Proof of Innocence: Upon withdrawal, Alice proves in ZK that the deposit was made from a non-blacklisted address.
- Problem: The list is updated infrequently.
- Viewing keys: When interacting with other properties, Alice can prove the properties of the trace.
- Problem: There is no standard, and no exchange will integrate this now, though it may work in the future.
- Involuntary Reveal Approach: Each transaction in the system must include encrypted “call data,” which can be decrypted by a (decentralized) governance that decides to reveal the trace.
- Problem: Who decides what to decrypt/reveal? DAO?
Future:
- All exchanges and on/off-ramps integrate viewing keys and proofs of innocence.
- Users decide what to reveal to whom.
- A perfectly interoperable and bulletproof system.
Now:
- An involuntary reveal component governed by a decentralized body.
- If the reveal system works well, legit users are happy, bad actors are repelled, and there’s no reason for sanctions.
Pushing the Performance and Usability of Zero Knowledge Proofs, Dan Dore (Lita) Slides Talk
Problem: zkSNARKs have a high learning curve for the tooling and high time, space, and energy costs.
There are three approaches to creating zk programs (circuits):
- DSLs provide abstraction on top of low-level constraint systems like R1CS or PLONK. They work as constraint-writing macros.
- The direct approach takes a GPL program and directly produces an equivalent circuit. This is hard to do and requires sophisticated compilers and tooling.
- ISA/VM is a hybrid approach. It uses an intermediary representation of a program, which is a set of instructions for a virtual machine.
DSL-based VMs require developers to learn new paradigms. The direct approach is hard to integrate with new crypto advances. “We hope that VM will be the way to use zk.”
Instead of using a RISC-V instruction set, Lita uses its own zk-friendly ISA, Valida ISA. A new compiler toolchain is introduced that can convert GPL to this new Valida ISA.
Valida architecture includes:
- 32-bit ALU chip.
- CPU chip.
- Memory RAM chip.
- Program ROM chip.
- 8-bit range checker chip.
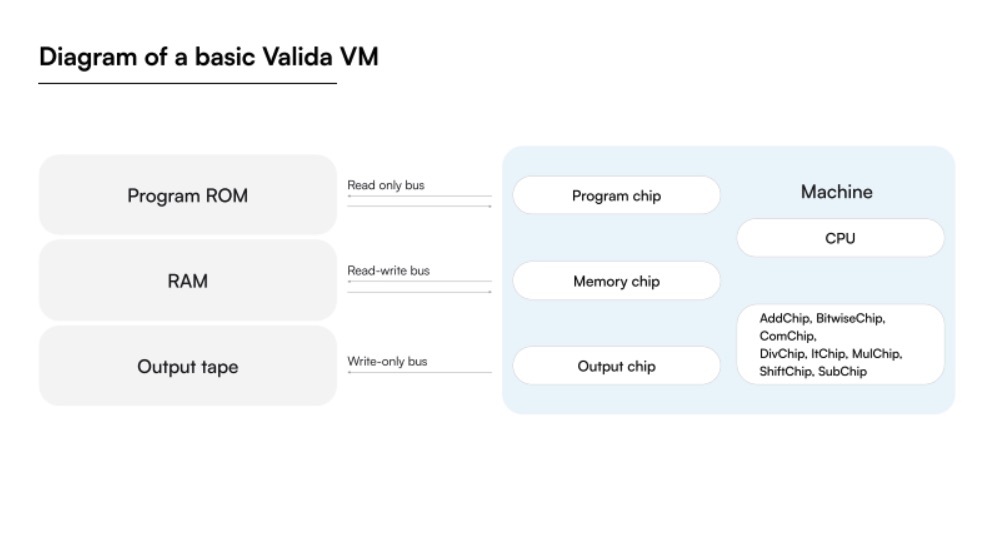
Execution engine:
- Runs Valida programs and generates execution traces.
Prover:
- Proves the output of a program by proving the existence of a valid execution trace.
- One execution trace for each chip: memory, arithmetic, CPU.
Verifier:
- Verifies the output of a program, given a proof.
Valida uses STARKs because it uses only hash functions, avoiding the need for EC and other expensive crypto operations. Valida uses small (32-bit) fields, namely the Baby bear field, because arithmetic in it looks similar to ordinary 32-bit arithmetic. However, since the field is small, challenges are drawn from a larger field—a degree 5 extension of the Baby bear field. The polynomial commitment scheme is FRI PCS.
Valida uses LLVM to generate an optimized intermediary representation (IR) from various frontends, then compiles LLVM IR to Valida assembly.
Valida is 993 times faster than Risc0.
https://github.com/valida-xyz/valida
Compiling to ZKVMs, Alberto Centelles Talk
A zkVM is an emulation of a CPU architecture (memory, stack, execution unit) as one universal circuit that can compute and prove any program from a given set of opcodes.
Problem: Compiling a program to a zkVM is a million times slower than compiling it directly into a circuit.
Stages of zkVM:
- Compilation: Compiles a program into a set of instructions.
- Execution: Generates the execution trace/witness.
- Proving: Here is where the different categories of zkVM come in.
- (Optional) Compressing (via a layer of recursion).
- (Optional) Zero-knowledge.
There are many approaches to zkVM:
- Conventional zkVMs: Describe each submodule (memory/stack/ALU/etc.) in a constraint system, generate SxARK, recursion, zk.
- (N)IVC zkVM: Split the statement, generate the proofs in parallel, and then prove the aggregation.
- GKR zkVM: Leverage code structure, compile into assembly, group identical opcodes, generate a proof for each group, aggregate.
- Jolt zkVM: Compile to disposable evaluation tables, Multilinear extensions (MLE), lookup.
- Mangrove SNARKs: Compile a program into identical steps, Data-parallel circuits, Apply a tree-based PCD.
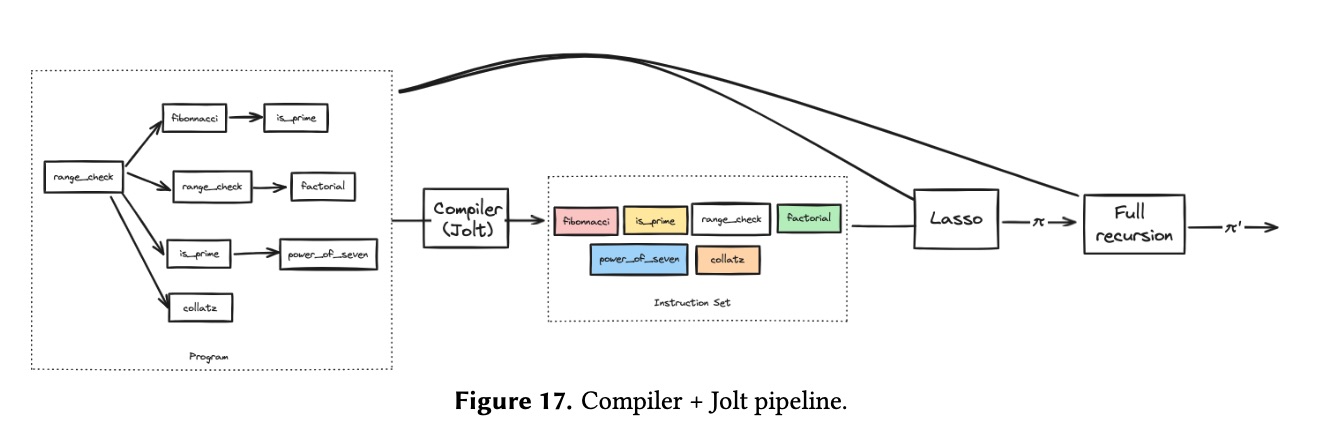
The future is to use all these together:
- Using a compiler to split the statement itself. Combine the pieces using IVC, GKR, Lasso.
- Abstractions outside the CPU unit: Blocks, co-processors, uniform chunks.
- Parallelism to achieve monolithic SNARK performance, Data-parallel circuits, Proof-Carrying Data.
- Use lookups.
SNARK proving ASICs, Justin Drake (Ethereum Foundation) Talk Slides
Problem: Every rollup on Ethereum is a silo, breaking down network effects and introducing fragmentation.
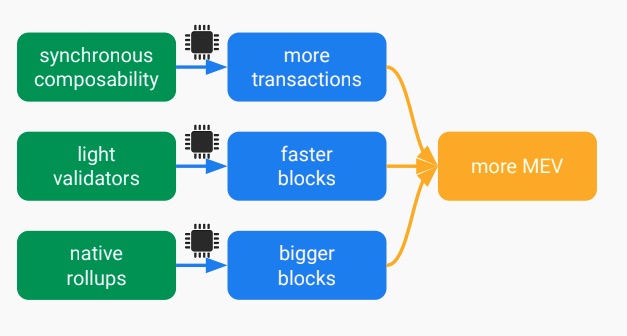
Motivation:
- Super-transactions that touch multiple rollups: Cross-rollup composability enables message passing between rollups and atomic assets bridging.
- Light clients: They can verify block validity in real time without relying on remote nodes, meaning the proof of block validity has to come along with the block.
- Native rollups: These natively reuse EVM as its VM, so no reimplementation of EVM circuits is needed. Deploying a new rollup is just one line of code.
Solution:
- Shared sequencer: Used by all rollups.
- Real-time proofs: Real-time means they are shorter than the Ethereum slot time (12 seconds), so they have to be less than 10 seconds, ideally 1 second.
- verifyEVM() precompile: This can verify an EVM transition within EVM.
Real-time proving unlocks:
- Real-time settlement, allowing synchronous composability, which allows for more transactions that require synchronous composability.
- (zk)snarked clients, allowing light validators, giving more time to build blocks and accept more transactions since you can start sealing later within the time slot.
- EVM-in-EVM precompile and native rollups, allowing for bigger blocks because you are verifying the rollup is constant, so no gas limit, only computation power.
All of this gives more MEV!
Problem: Real-time proofs are expensive.
Solution: ASIC acceleration.
ZK-ASIC is hardware that makes primitive crypto operations constant (one-clock cycle).
ASIC is not programmable, so the idea is to freeze the witness and proof generator algorithm into ASIC circuit, and give to the circuit some intermediary RISC-V bytecode.
For zkSNARKs on mobile phones, one idea may be to do the ZK part on the phone and SNARK part on the backend.
MPC-Enabled Proof Market, Daniel Kales Talk
Problem: A client willing to outsource proof generation to the prover has to provide (and hence disclose) a secret witness to the prover.
MPC enables private and secure computation between parties without disclosing their inputs.
Solution: Execute the prover inside MPC. The client provides a secret witness as a private input. The prover carries out the computation and outputs a proof.
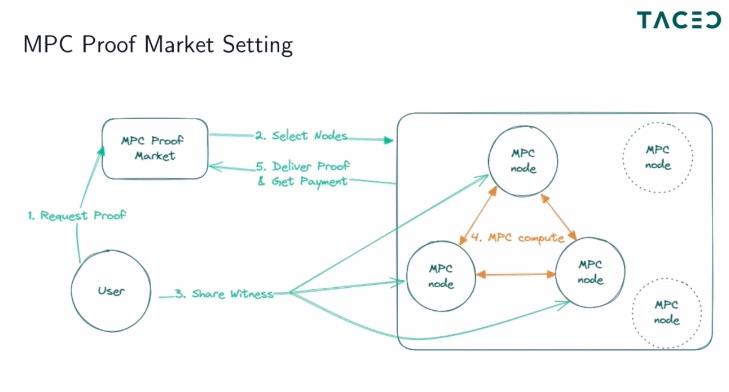
KZG and IPA are MPC-friendly, but FRI-based vector commitments are non-MPC-friendly.
Challenge: Extended Witness Generation; many gadgets may be MPC-unfriendly.
Conclusion:
- ZK and MPC can be a good fit.
- Challenges in Extended Witness Generation and selection of parties.
- Combination of MPC and ZK research is needed.
- Hundreds of ZK research papers exist, but very few on the MPC-ZK intersection.
- MPC investigation/implementation of “production” systems is needed.
Binius: a Hardware-Optimized SNARK, Jim Posen (Ulvetanna) Talk Slides
Majority of the computation of proof systems spend their time in:
- Generating the witness — storing the trace of registered and memory states over time. Not computationally expensive but tricky to parallelize.
- Committing the witness (fancy hashing, Reed-Solomon encoding (NTT), merkleization, EC MSM).
- Vanishing argument (lots of arithmetic circuit evaluations), polynomial divisibility check, or interactive sum check protocol, which boils down to polynomial evaluations or arithmetic circuit evaluations at different points.
- Opening proof (not significant).
Problem: Almost 50% of Plonky provers spend their time at the commitment phase (hashing, Keccak, or Poseidon).
Solution: Use binary fields because they are a better primitive for fast verifiable computing.
For prime fields, addition is integer addition with conditional subtraction, while for binary fields, it’s just bitwise XOR.
For prime fields, multiplication is integer multiplication with a reduction method, while for binary fields, it’s carry-less multiplication with a reduction method.
The Vision Mark Hash uses an arithmetisation-optimized hash function over Binary Tower Fields.
Thanks to these optimizations, the bottleneck becomes Vanishing, which can be optimized using hardware.

The Role of Decentralized Proving in the Modular Stack, Uma Roy (Succinct) Slides Talk
When Ethereum initially launched, we had a base layer responsible for execution, settlement, consensus, and data availability.
Today, when a user sends a transaction, it goes through specialized networks:
- Sequencing (Espresso, Astria, SUAVE, OP Superchain).
- Execution (Arbitrum Orbit, OP Stack, Polygon CDK, SVM L2, Move L2, Warm L2).
- DA (4844, Celestia, Avail, EigenDA).
- Proving.
- Interop (Polygon, AggLayer, OP Superchain).
- Settlement (Ethereum, Bitcoin, Celestia SNARK accts).
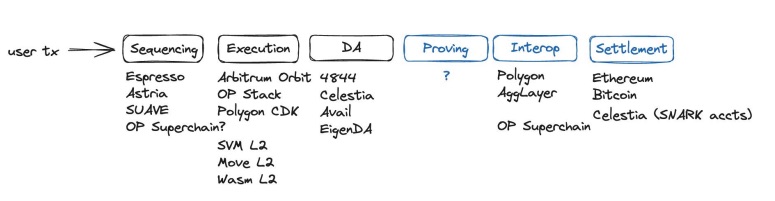
Problem: Most of those components do not use zkSNARKs. In a production context, they use multisigs. Polygon CDK is the only one using zkSNARKs in practice.
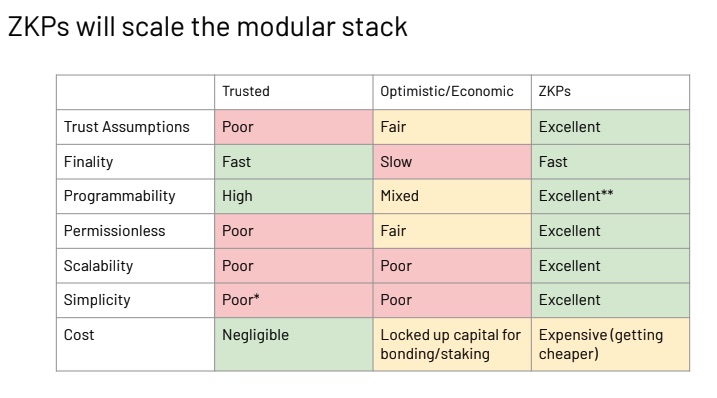
Solution: A general-purpose, performant zkVM like SP1 will catalyze wide adoption in the modular stack. Every rollup will be a zkRollup.
Currently, Rollups work as follows:
- Rollups send proof requests to the proving network or proving service.
- Provers fulfill those proof requests.
- Proofs are aggregated.
- Proofs are verified on-chain (ETH, BTC, Solana, etc.).
- We don’t have to prove the provers because if it gets verified on-chain, it’s correct.
Problem: Each rollup is a kind of isolated silo, building proprietary stacks.
Solution: A Unified Proving Protocol.
- Rollups send proof requests to a standardized pool of proof requests (using a standardized API).
- Provers (different companies) claim the proof requests and bid on the proof pricing.
- Fulfilled proofs are published to a pool of fulfilled proofs.
- Relayed on-chain.
A Unified Protocol Provides:
- A shared standard for competitive price discovery among a diverse set of provers.
- An easier development experience.
- Economies of scale and better resource utilization, resulting in cheaper prices.
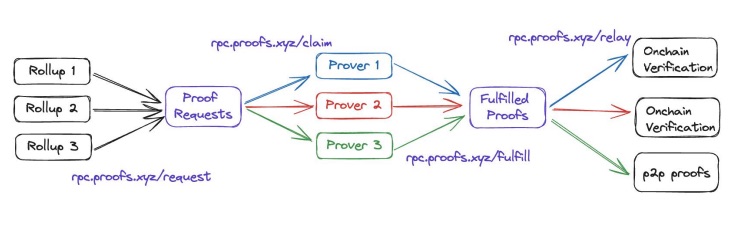
Problem: It’s hard to create an open proving marketplace without proof mining or proof racing, both causing redundant work, leading to increased costs.
Solutions:
- PoS Issuance Model: Fixed amount of reward per ZK proof per block.
- Auction Model: A competitive auction for each proof request.
More on this in Wenhao Wang’s talk.

ZK Fireside, Georgios Konstantopoulos, Nicolas Mohnblatt, Alex Evans
- Client-side optimizes for latency, while server-side optimizes for throughput.
- Client-side enables privacy, server-side enables scalability.
- Client-side is zk, server-side is SNARK.
The divide between server and client-side will disappear as we move to collaborative proving, where every server will also be a client because it needs to pass the proof to others.
In the ZKP world, proving time is a game-changer: one second is fantastic, ten seconds is terrible.
A co-processor is anything that offloads the computation:
- SHA256 hardware acceleration is a co-processor to the CPU.
- Rollup is a co-processor to Ethereum.
- ZK ASIC is a co-processor to rollup.
Everyone is doing application-specific co-processors.
Opening storage proofs across rollups is a form of co-processor, which unlocks state composition between rollups.
To make money in the MEV, you need to be:
- In a critical path of the transaction supply chain, or
- At the edges of the transaction supply chain.
You monetize either the user or the infrastructure. The closer to the middle the player is (e.g., Alchemy), the more it needs to move outwards to sustainably capture value.
The same pattern will play out in the proof supply chain. To make money in the Proof supply chain:
- Own the user (the wallet), or
- Own the VM.
The VM is a hard piece of software to commoditize in a vacuum; you need to own another layer of the stack (like a prover marketplace).
If you are a Prover Network, it makes sense to give the zkVM for free because that drives the demand to your Prover Network.
We need hardware because proofs are big, proofs are slow, and statements are only getting bigger over time.
We should work backward from what is the optimal proof generation pipeline.
The optimal pipeline looks like this:
- Bunch of transactions coming in,
- All of them are client-side proven on users’ end-devices on hardware-accelerated SNARKs,
- Transactions are being aggregated, self-composed, and recursed.
We should not be afraid of building hardware acceleration. We don’t need to go all the way to the optimal thing. It’s okay to iterate. Once you find product-market fit, you can take down the costs.
A rollup is a very high-margin business; it charges a large amount of fees. Each hardware company has to pick its customer, understand their cost structure and performance needs, and build accordingly.
People love to self-build everything, but you can always buy a solution to accelerate your time to market.
Shipping a product is a hard thing to convince yourself to do sometimes in crypto. You can sell a token, sell a narrative, and keep working on infrastructure. There is a very toxic narrative in crypto that we need to delete from our brains.
Conclusion
ZK is a fascinating space, stretched by exploration and disruption on one side and standardization and unification on the other. Nonetheless, it seems to balance chaos and control in a decentralized manner. Without one big player coordinating the whole industry, there’s disruption and exploration balanced with the control of standardization and unification.
There seems to be a false premise that if a system distributes some trusted component with MPC, blockchain, or multi-sig, it solves the centralization problem, making the system decentralized and secure. But in practice, if there is no incentive to run the software as an independent party, and the “network” consists of nodes controlled by a single organization, then it’s still a TTP. The system achieves fault tolerance, but it should not be considered decentralized/censorship-resistant or secure.
Decentralized prover networks (aka Proof of Work 2.0) are a new trend of creating a marketplace where specialized provers compete for generating proofs for large statements (e.g., correctness of a bundle of transactions in a rollup).
We can observe a trend where more and more components are getting encapsulated into dedicated specialized networks. The future looks very much like X-as-a-Service (or hopefully X-as-a-Network): Data Availability-as-a-Network, Execution-as-a-Network, ThresholdCrypto-as-a-Network, Proving-as-a-Network, Consensus-as-a-Network, Randomness-as-a-Network, and others.
Building a new protocol looks more like gluing together many networks. This seems to be great. However, as with any big distributed system, the complexity of connecting and managing them may outgrow the complexity of building integrated specialized components.
zkVM seems to be becoming THE ZK. Similar to how DNNs became the ML, LLMs became THE AI, LLVM became THE COMPILER, Ethernet became THE DATA LINK, and HTTP became THE INTERNET PROTOCOL.
Technological convergence may appear limiting and sub-optimal, but it may be the way forward. Optimizing one foundational platform improves everything built on top of it, accelerating mass adoption and capturing value for further research and development. As a side effect, it nurtures peripheral projects, leading to unpredictable discoveries.
Right now, client-side proving is lagging behind, mainly because the money is in server-side proving. The biggest limitation is memory. It’s suggested to do the ZK part on the phone and the SNARK part on the backend. MPC-ZK looks promising to achieve this.
Final words
ZK seems to be becoming a synonym for cryptography. Everything that uses cryptography is ZK. The word ZK becomes more capacious and vague. This may lead to confusion and the ever-present impostor syndrome. However, we have to remember that:
“ZK is the Endgame. This is how we do it.”
~Daniel Lumi
